本文来自:Bixocean
为 SKU-11020201-0001 双目相机的使用指南。
双目相机标定的必要性:
OpenCV 双目相机标定是一种用于校准双目相机系统的过程,以消除相机畸变并确定相机之间的相对位置和方向。通过标定,我们可以获得准确的相机内参和外参,为双目视觉应用(如深度估计和三维重建)提供基础。
请注意由于水下存在光线的折射反射等,相机的标定需在水中进行,摄像头在水下的视角与在空气中存在区别。
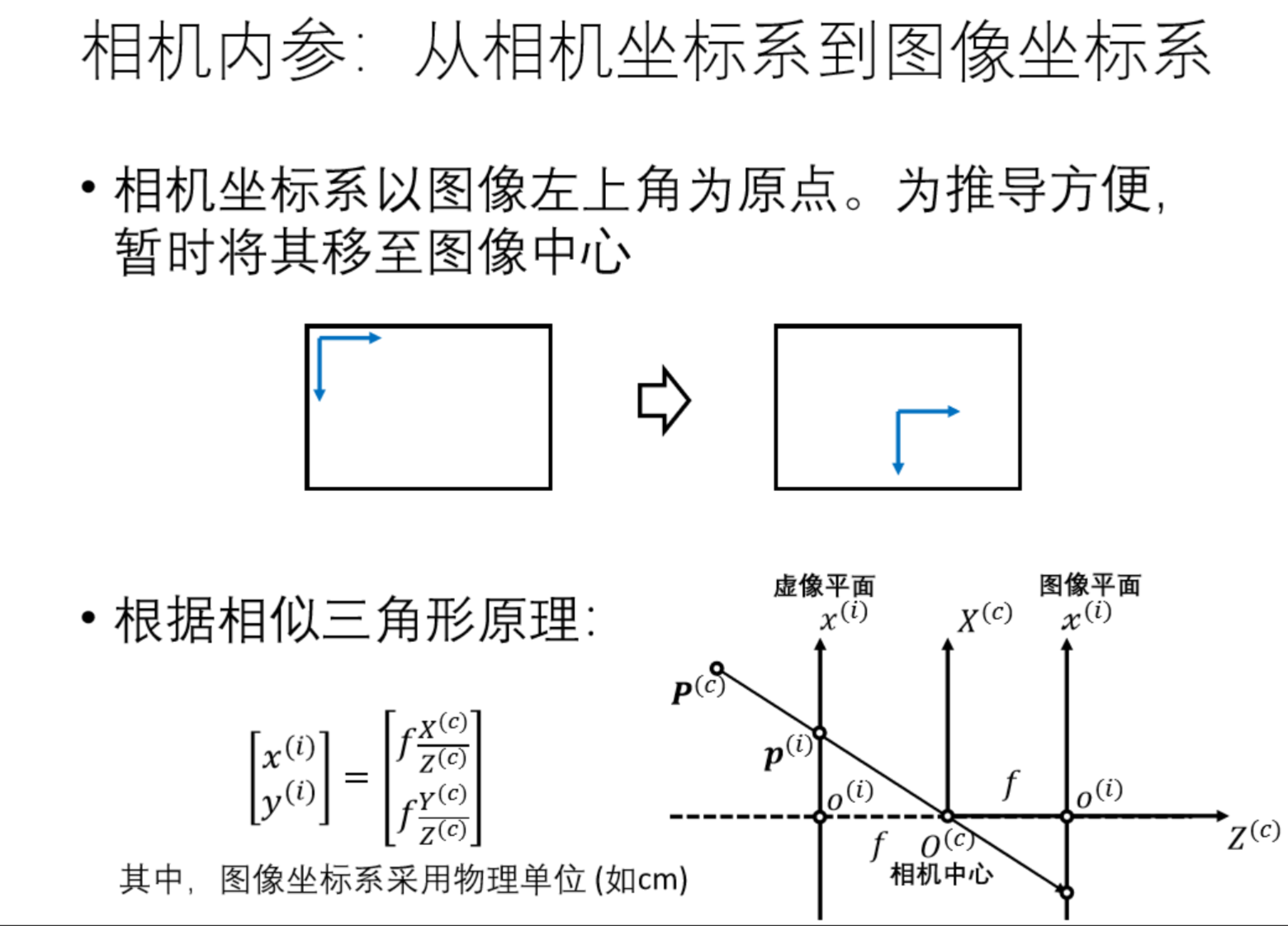
双目相机标定涉及使用一个标定板,该标定板包含已知几何形状的图案。相机对准标定板并拍摄一系列图像。这些图像用于计算相机内参(如焦距、畸变系数)和外参(如平移和旋转)。
相机标定原理:
- 针孔相机模型:通过标定板(棋盘格)的三维坐标与图像二维坐标的映射关系,求解相机内参矩阵(焦距、主点坐标)与畸变系数(径向、切向畸变)。
- 双目视觉模型:通过
stereoCalibrate算法计算左右相机的相对位姿(旋转矩阵 R、平移向量 T),建立双目视觉坐标系转换关系。
标定参数表
| 参数名称 | 符号 | 维度 | 物理意义 |
| 左相机内参矩阵 | K1 | 3×3 | 包含焦距(fx/fy)、主点坐标(cx/cy) |
| 左相机畸变系数 | D1 | 1×5 | 径向畸变(k1,k2,k3)与切向畸变(p1,p2) |
| 右相机内参矩阵 | K2 | 3×3 | 同上 |
| 右相机畸变系数 | D2 | 1×5 | 同上 |
| 旋转矩阵 | R | 3×3 | 右相机相对于左相机的旋转变换 |
| 平移向量 | T | 3×1 | 右相机相对于左相机的平移变换 |
| 重投影矩阵 | Q | 4×4 | 视差到三维坐标的转换矩阵 |
可直接使用标定软件工具进行快速标定,也可以使用 Python 程序进行标定,可自行进行程序修改。以下为使用 Python 程序进行标定的过程。
第一步:连接水下双目相机

使用 USB 数据线将双目摄像头与 PC 电脑连接。
第二步:收集标定板图像
获取标定板
- 前往www.calib.io网站
- 获取所需的标定板

这里可以更改各种参数,我们这里选择的是:
Rows 7;
Columns 10;
Checker Width 35mm然后点击 Save Pattern as PDF 打印标定板(务必按实际尺寸打印,并且需挑选防水材质,因为要进行水下标定,可以使用雪弗板打印)。
收集标定图像
代码资料:
文件夹结构
.
├── 双目相机标定和测距
│ ├── code
│ │ ├── 标定.py
│ │ ├── 测距.py
│ │ └── 拍摄.py
│ ├── data
│ │ ├── calibration
│ │ │ ├── left
│ │ │ ├── right
│ │ │ └── config
│ └── README.md先打开“拍摄.py”文件。
import cv2
import numpy as np
import os
def open_stereo_camera(index=1, width=2560, height=720):
"""
打开双目摄像头并获取左右画面
index: 相机设备索引
width: 期望的视频流宽度
height: 期望的视频流高度
"""
# 使用CAP_DSHOW参数打开相机,解决单目显示问题
cap = cv2.VideoCapture(index + cv2.CAP_DSHOW)
if not cap.isOpened():
print(f"无法打开相机索引 {index}")
return None, None, False
# 设置视频流分辨率
cap.set(cv2.CAP_PROP_FRAME_WIDTH, width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
# 验证分辨率设置
current_width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
current_height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
print(f"相机已打开,当前分辨率: {current_width}x{current_height}")
return cap, width, height
def get_stereo_frames(cap, width, height):
"""从双目相机获取左右画面"""
ret, frame = cap.read()
if not ret:
print("无法获取相机画面")
return None, None, False
# 检查画面尺寸是否符合预期
if frame.shape[1] != width or frame.shape[0] != height:
print(f"警告:实际画面尺寸 {frame.shape[1]}x{frame.shape[0]} 与设置的 {width}x{height} 不符")
# 将画面分割为左右两部分
half_width = width // 2
frame_left = frame[:, :half_width]
frame_right = frame[:, half_width:]
return frame_left, frame_right, True
def display_stereo_frames(frame_left, frame_right):
"""显示左右相机画面"""
cv2.imshow("Left Camera", frame_left)
cv2.imshow("Right Camera", frame_right)
# 显示辅助线(可选)
cv2.line(frame_left, (frame_left.shape[1]//2, 0),
(frame_left.shape[1]//2, frame_left.shape[0]), (0, 255, 0), 1)
cv2.line(frame_right, (frame_right.shape[1]//2, 0),
(frame_right.shape[1]//2, frame_right.shape[0]), (0, 255, 0), 1)
cv2.imshow("Combined View", np.hstack([frame_left, frame_right]))
def main():
# 相机参数(根据实际情况调整)
camera_index = 1 # 相机设备索引
frame_width = 2560 # 视频流宽度
frame_height = 720 # 视频流高度
# 保存目录
left_dir = "./data/calibration/left"
right_dir = "./data/calibration/right"
# 创建保存目录(如果不存在)
os.makedirs(left_dir, exist_ok=True)
os.makedirs(right_dir, exist_ok=True)
# 打开相机
cap, width, height = open_stereo_camera(camera_index, frame_width, frame_height)
if cap is None:
return
print("\n操作说明:")
print(" 按 'q' 键退出程序")
print(" 按 's' 键保存当前左右画面至指定目录")
try:
while True:
# 获取左右画面
frame_left, frame_right, ret = get_stereo_frames(cap, width, height)
if not ret:
break
# 显示画面
display_stereo_frames(frame_left, frame_right)
# 处理按键事件
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('s'):
# 生成时间戳文件名
timestamp = cv2.getTickCount() // 1000
left_filename = os.path.join(left_dir, f"left_{timestamp}.jpg")
right_filename = os.path.join(right_dir, f"right_{timestamp}.jpg")
# 保存画面
cv2.imwrite(left_filename, frame_left)
cv2.imwrite(right_filename, frame_right)
print(f"已保存左右画面:")
print(f" 左相机: {left_filename}")
print(f" 右相机: {right_filename}")
finally:
# 释放资源
cap.release()
cv2.destroyAllWindows()
print("程序已退出")
if __name__ == "__main__":
main()
如果相机没有正常显示,请进入main函数中修改camera_index参数(一般为0或1),然后运行。
操作说明:
按 'q' 键退出程序
按 's' 键保存当前左右画面至指定目录
收集大概20张左右即可
第三步:进行标定
打开“标定.py”文件并运行。
#-*- coding:utf-8 -*-
import os
import numpy as np
import cv2
import glob
import argparse
import json
import pickle
class Stereo_Camera_Calibration(object):
def __init__(self, width, height, lattice):
self.width = width # 棋盘格宽方向黑白格子相交点个数
self.height = height # 棋盘格长方向黑白格子相交点个数
self.lattice = lattice
# 设置迭代终止条件
self.criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
self.criteria_stereo = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 1e-5)
# =========================== 双目标定 =============================== #
def stereo_calibration(self, file_L, file_R):
# 设置 object points, 形式为 (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
objp = np.zeros((self.width * self.height, 3), np.float32) #我用的是6×9的棋盘格,可根据自己棋盘格自行修改相关参数
objp[:, :2] = np.mgrid[0:self.width, 0:self.height].T.reshape(-1, 2)
objp *= self.lattice
# 用arrays存储所有图片的object points 和 image points
objpoints = [] # 3d points in real world space
imgpointsR = [] # 2d points in image plane
imgpointsL = []
for i in range(len(file_L)):
ChessImaL = cv2.imread(file_L[i],0) # 左视图
ChessImaR = cv2.imread(file_R[i],0) # 右视图
retL, cornersL = cv2.findChessboardCorners(ChessImaL,(self.width, self.height), cv2.CALIB_CB_ADAPTIVE_THRESH | cv2.CALIB_CB_FILTER_QUADS) # 提取左图每一张图片的角点
retR, cornersR = cv2.findChessboardCorners(ChessImaR,(self.width, self.height), cv2.CALIB_CB_ADAPTIVE_THRESH | cv2.CALIB_CB_FILTER_QUADS) # 提取右图每一张图片的角点
if (True == retR) & (True == retL):
objpoints.append(objp)
cv2.cornerSubPix(ChessImaL, cornersL, (11, 11), (-1, -1), self.criteria) # 亚像素精确化,对粗提取的角点进行精确化
cv2.cornerSubPix(ChessImaR, cornersR, (11, 11), (-1, -1), self.criteria) # 亚像素精确化,对粗提取的角点进行精确化
imgpointsL.append(cornersL)
imgpointsR.append(cornersR)
ret_l = cv2.drawChessboardCorners(ChessImaL, (self.width, self.height), cornersL, retL)
#cv2.imshow(file_L[i], ChessImaL)
cv2.waitKey()
ret_r = cv2.drawChessboardCorners(ChessImaR, (self.width, self.height), cornersR, retR)
#cv2.imshow(file_R[i], ChessImaR)
cv2.waitKey(500)
# 相机的单双目标定、及校正
# 左侧相机单独标定
retL, K1, D1, rvecsL, tvecsL = cv2.calibrateCamera(objpoints,imgpointsL,ChessImaL.shape[::-1], None, None)
# 右侧相机单独标定
retR, K2, D2, rvecsR, tvecsR = cv2.calibrateCamera(objpoints,imgpointsR,ChessImaR.shape[::-1], None, None)
# --------- 双目相机的标定 ----------#
flags = 0
flags |= cv2.CALIB_FIX_INTRINSIC # K和D个矩阵是固定的。这是默认标志。如果你校准好你的相机,只求解𝑅,𝑇,𝐸,𝐹。
#flags |= cv2.CALIB_FIX_PRINCIPAL_POINT # 修复K矩阵中的参考点。
# flags |= cv2.CALIB_USE_INTRINSIC_GUESS # K和D个矩阵将被优化。对于这个计算,你应该给出经过良好校准的矩阵,以便(可能)得到更好的结果。
#flags |= cv2.CALIB_FIX_FOCAL_LENGTH # 在K矩阵中固定焦距。
# flags |= cv2.CALIB_FIX_ASPECT_RATIO # 固定长宽比。
#flags |= cv2.CALIB_ZERO_TANGENT_DIST # 去掉畸变。
# 内参、畸变系数、平移向量、旋转矩阵
retS, K1, D1, K2, D2, R, T, E, F = cv2.stereoCalibrate(objpoints,imgpointsL,imgpointsR,K1,D1,K2,D2,
ChessImaR.shape[::-1], self.criteria_stereo,flags)
# 左内参矩阵、左畸变向量、右内参矩阵、右畸变向量、旋转矩阵、平移矩阵
return K1, D1, K2, D2, R, T
# ==================================================================== #
# =========================== 双目校正 =============================== #
# 获取畸变校正、立体校正、重投影矩阵
def getRectifyTransform(self, width,height,K1 ,D1 ,K2 ,D2 , R, T):
#得出进行立体矫正所需要的映射矩阵
# 左校正变换矩阵、右校正变换矩阵、左投影矩阵、右投影矩阵、深度差异映射矩阵
R_l,R_r,P_l,P_r,Q, roi_left, roi_right = cv2.stereoRectify(K1, D1, K2, D2,
(width, height),R, T,
flags=cv2.CALIB_ZERO_DISPARITY, alpha=0)
# # 标志CALIB_ZERO_DISPARITY,它用于匹配图像之间的y轴
# 计算畸变矫正和立体校正的映射变换。
map_lx, map_ly = cv2.initUndistortRectifyMap(K1, D1, R_l, P_l, (width,height),cv2.CV_32FC1)
map_rx, map_ry = cv2.initUndistortRectifyMap(K2, D2, R_r, P_r, (width,height),cv2.CV_32FC1)
return map_lx, map_ly,map_rx, map_ry, Q
# 得到畸变校正和立体校正后的图像
def get_rectify_img(self, imgL, imgR,map_lx, map_ly,map_rx, map_ry):
rec_img_L = cv2.remap(imgL,map_lx, map_ly, cv2.INTER_LINEAR, cv2.BORDER_CONSTANT) # 使用remap函数完成映射
rec_img_R = cv2.remap(imgR,map_rx, map_ry, cv2.INTER_LINEAR, cv2.BORDER_CONSTANT)
return rec_img_L, rec_img_R
# 立体校正检验——极线对齐
def draw_line(self, rec_img_L,rec_img_R):
#建立输出图像
width = max(rec_img_L.shape[1],rec_img_R.shape[1])
height = max(rec_img_L.shape[0],rec_img_R.shape[0])
output = np.zeros((height,width*2,3),dtype=np.uint8)
output[0:rec_img_L.shape[0],0:rec_img_L.shape[1]] = rec_img_L
output[0:rec_img_R.shape[0],rec_img_L.shape[1]:] = rec_img_R
# 绘制等间距平行线
line_interval = 50 # 直线间隔:50
for k in range(height // line_interval):
cv2.line(output, (0, line_interval * (k + 1)), (2 * width, line_interval * (k + 1)), (0, 255, 0), thickness=2, lineType=cv2.LINE_AA)
return output # 可显示的图像
# ===================================================================== #
def get_parser():
parser = argparse.ArgumentParser(description='Camera calibration')
parser.add_argument('--width', type=int, default=9, help='chessboard width size')
parser.add_argument('--height', type=int, default=6, help='chessboard height size')
parser.add_argument('--lattice', type=float, default=35, help='lattice length')
parser.add_argument('--image_dir', type=str, default="data/calibration/", help='images path')
parser.add_argument('--save_dir', type=str, default="data/config/", help='path to save file')
parser.add_argument('--file_name', type=str, default="camera_params", help='camera params save file')
return parser
def get_file(path): #获取文件路径
img_path = []
for root, dirs, files in os.walk(path):
for file in files:
img_path.append(os.path.join(root,file))
return img_path
if __name__ == "__main__":
args = get_parser().parse_args()
params_dict = {}
file_L = get_file(args.image_dir + 'left')
file_R = get_file(args.image_dir + 'right')
print("file_L:", len(file_L))
print("file_R:", len(file_R))
imgL = cv2.imread(file_L[2])
imgR = cv2.imread(file_R[2])
height, width = imgL.shape[0:2]
calibration = Stereo_Camera_Calibration(args.width, args.height, args.lattice)
left_K,left_D, right_K, right_D, R, T = calibration.stereo_calibration(file_L, file_R)
map_lx, map_ly,map_rx, map_ry, Q = calibration.getRectifyTransform(width,height,left_K,left_D,
right_K, right_D, R, T)
# 查看校正效果
img_ = calibration.draw_line(imgL,imgR)
#cv2.imshow("img",img_)
rec_img_L, rec_img_R = calibration.get_rectify_img(imgL,imgR,map_lx, map_ly,map_rx, map_ry)
img_show = calibration.draw_line(rec_img_L,rec_img_R)
#cv2.imshow("output",img_show)
cv2.waitKey(0)
params_dict['size'] = [width, height] # 图像的宽度和高度。
params_dict['K1'] = left_K.tolist() # 左相机的内参矩阵。
params_dict['D1'] = left_D.tolist() # 左相机的畸变系数。
params_dict['K2'] = right_K.tolist() # 右相机的内参矩阵。
params_dict['D2'] = right_D.tolist() # 右相机的畸变系数。
params_dict['map_lx'] = map_lx.tolist() # 左相机的畸变校正映射矩阵。
params_dict['map_ly'] = map_ly.tolist() # 左相机的畸变校正映射矩阵。
params_dict['map_rx'] = map_rx.tolist() # 右相机的畸变校正映射矩阵。
params_dict['map_ry'] = map_ry.tolist() # 右相机的畸变校正映射矩阵。
params_dict['R'] = R.tolist() # 右相机相对于左相机的旋转矩阵。
params_dict['T'] = T.tolist() # 右相机相对于左相机的平移向量。
params_dict['Q'] = Q.tolist() # 重投影矩阵,用于从视差图计算三维坐标。
# =========== 保存相机参数 =========== #
# 保存为.json文件
file_path = args.save_dir + args.file_name + ".json"
with open(file_path,"w") as f:
json.dump(params_dict, f, indent=1)
print("ALL Make Done!")
在get_parser()函数中,width和height参数可以在default=xx中修改 比如我使用的是7x10的标定板(7行10列) 但是在opencv中参数含义如下:
--width:棋盘格宽方向角点数量,故为9--height:棋盘格高方向角点数量,故为6--lattice:棋盘格方格边长(单位:mm,默认:35)
也就是说,如果标定板的大小为X*Y 那么,
width = Y-1
Height = X-1
稍等片刻,等待打印台输出"ALL Make Done!" 后说明参数文件 已经生成并保存至./data./config目录下了。
第四步:相机测距
这一步的目的是为了检验上一步的相机标定是否成功。
- 先打开“测距.py”并运行
- 将摄像头对准标定板
- 会自动弹出该图像界面

由图可见,每一个小格子的间距约为35mm,这与我们实际的标定板大小参数一致,说明相机标定成功!
双目深度估计:
在测距.py文件运行中,同时有depth图像生成。
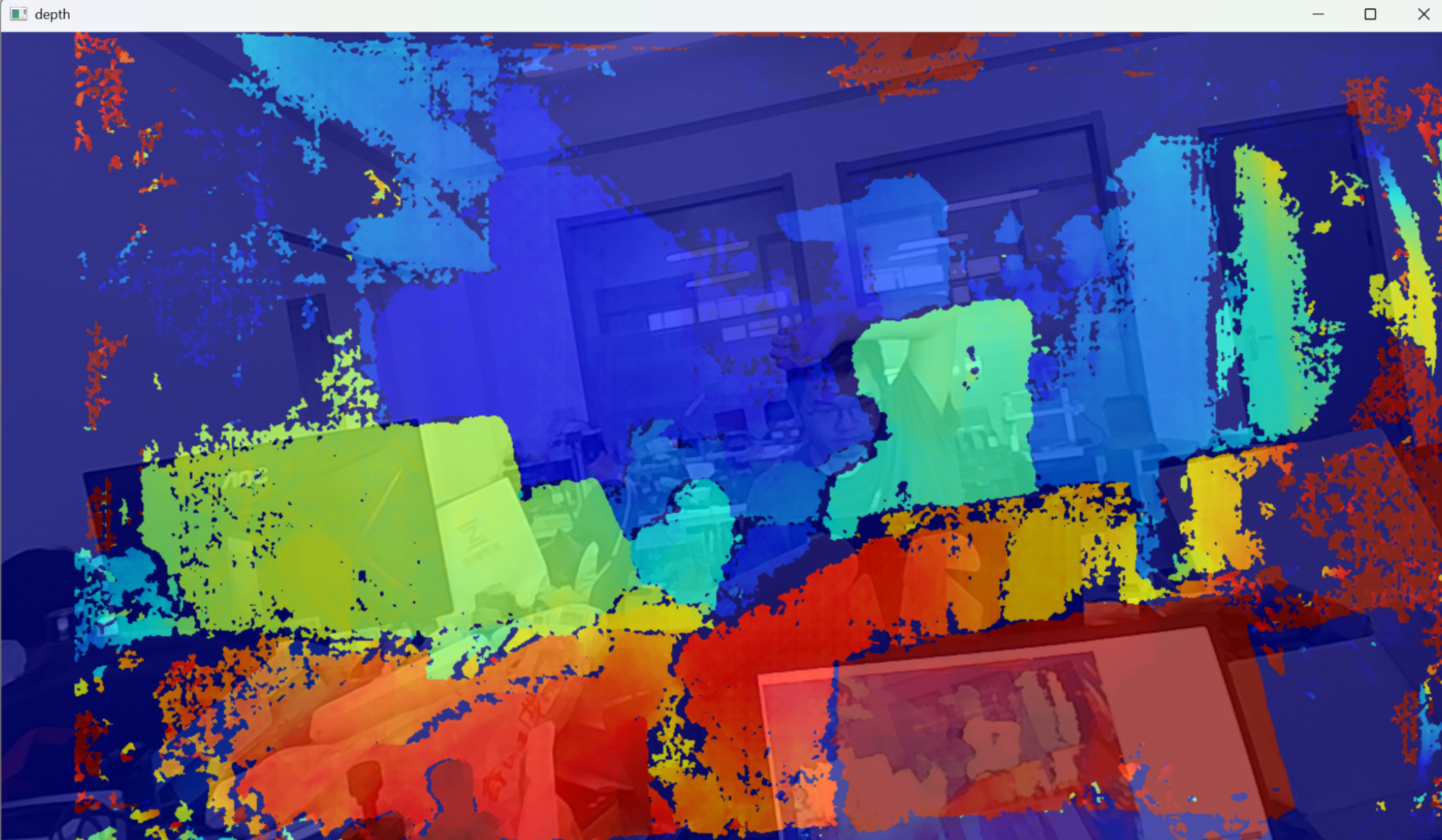
该图像反应的是图像的深度信息。
其中暖色(红色)代表距离近,冷色(蓝色)代表距离远。
深度计算原理
视差 - 深度转换基础
- 视差的定义:同一物体在左右相机成像中的水平位置差异,单位为像素。
- 三角测量原理:利用左右相机的基线距离(两镜头光心间距)和焦距,通过视差计算物体的三维坐标。
- 重投影矩阵 Q:将像素视差转换为三维坐标的关键矩阵,公式如下:
[X, Y, Z, 1]^T = Q * [u, v, d, 1]^T其中:
- (u, v)为像素坐标,d为视差
- (X, Y, Z)为三维空间坐标
- Q 的构造包含相机内参、外参和基线距离等参数
算法实现流程
(1) 相机标定与校正
# 读取标定参数(从JSON文件加载)
with open(file_path, "r") as f:
params_dict = json.load(f)
# 立体校正:生成重投影矩阵Q和映射表
R1, R2, P1, P2, Q, validPixROI1, validPixROI2 = cv2.stereoRectify(
left_camera_matrix, left_distortion,
right_camera_matrix, right_distortion, size, R, T
)
# 生成映射表,用于图像校正
left_map1, left_map2 = cv2.initUndistortRectifyMap(...)- 原理:通过
stereoRectify函数计算校正参数,使左右相机成像平面平行,简化立体匹配。 - 作用:校正后的图像中,同一物体的像素位于同一水平扫描线,减少匹配复杂度。
(2) 立体匹配(SGBM 算法)
# 初始化SGBM匹配器
stereo = cv2.StereoSGBM_create(
minDisparity=1,
numDisparities=64,
blockSize=3,
P1=8 * img_channels * blockSize * blockSize,
P2=32 * img_channels * blockSize * blockSize,
# 其他参数...
)
# 计算视差图
disparity = stereo.compute(img1_rectified, img2_rectified)- SGBM 算法核心:半全局匹配:结合局部块匹配和全局能量优化,平衡精度与速度。参数解析:
blockSize:匹配块大小,越大对纹理不敏感区域越鲁棒。P1/P2:控制视差平滑度,P2 需大于 P1 以避免过度平滑。numDisparities:最大视差范围,需为 16 的倍数。
(3) 视差 - 深度转换
# 三维重建:视差图→三维坐标
threeD = cv2.reprojectImageTo3D(avg_disparity, Q, handleMissingValues=True)
threeD = threeD * 16 # 视差单位转换(OpenCV默认乘16)